Honestly, most people approach an r tutorial in r completely backwards. They start with the syntax of vectors or the dry history of S, the language R was based on. That's a mistake. It’s like trying to learn how to drive by studying the chemical composition of gasoline. You don't need to know the internal combustion engine to get to the grocery store, and you don't need to be a computer scientist to start cleaning data in R.
R is weird. It’s built by statisticians, not software engineers. This means it behaves in ways that might make a Python developer scream into their keyboard, but for someone trying to understand a messy spreadsheet, it's actually kind of a superpower.
The Setup That Actually Works
Don't just download R. If you do that, you're staring at a white terminal that looks like it belongs in 1985.
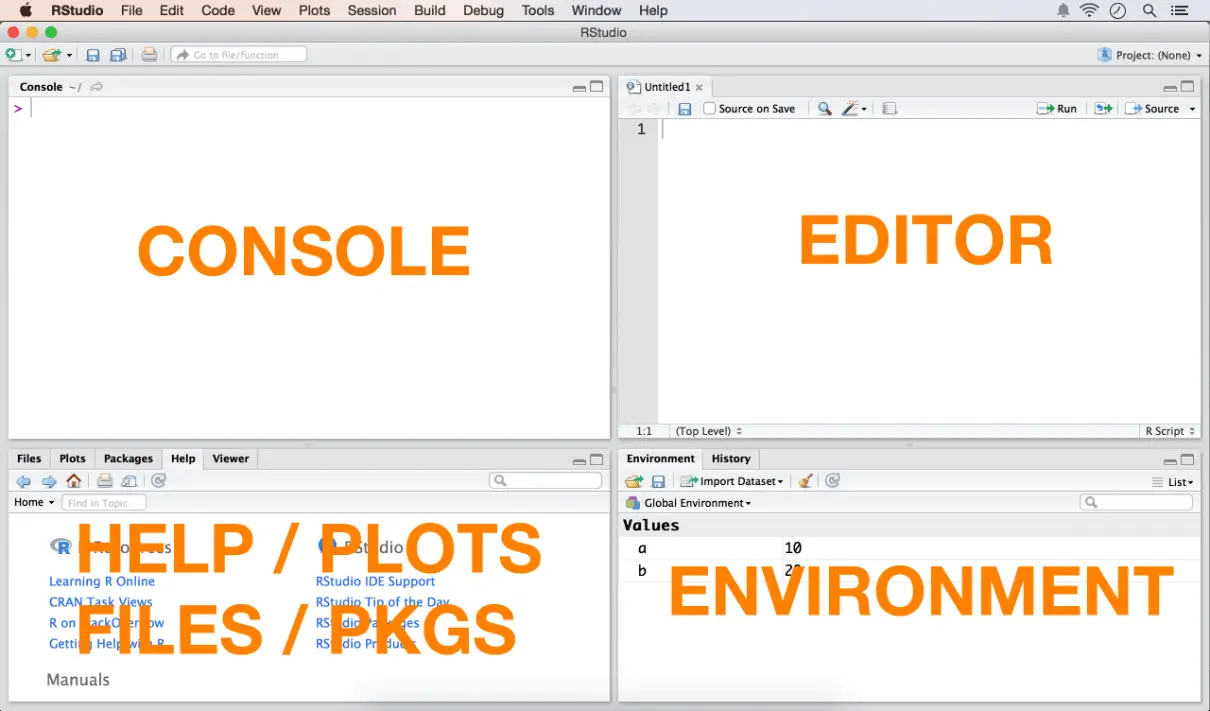
You need RStudio (now technically part of Posit). It’s the Integrated Development Environment (IDE) that makes R usable. Think of R as the engine and RStudio as the dashboard, steering wheel, and heated seats.
Once you have RStudio open, the first thing you should do in any r tutorial in r is ignore the "Console" for a second and open a script file. Why? Because the Console is a goldfish. It forgets everything the moment you hit Enter. A script is your diary.
CRAN and the Library Logic
The Comprehensive R Archive Network, or CRAN, is the backbone of the R world. It’s a curated collection of packages that extend what R can do. It’s remarkably stable. Unlike some other languages where packages break every three weeks, CRAN has strict rules. If a package doesn't meet the standards, the "CRAN Task Force" (yes, that's a real thing) will kick it off.
To get anything done, you’ll likely use the Tidyverse. It’s a collection of packages—like ggplot2 for charts and dplyr for data manipulation—that share a common philosophy. Hadley Wickham, the Chief Scientist at Posit, is the primary architect here. His philosophy is that data should be "tidy": each variable is a column, and each observation is a row. Sounds simple. It's actually revolutionary for data cleaning.
Why You Should Stop Using Base R Right Away
There is a heated debate in the R community. Purists love "Base R." They like the brackets and the dollar signs. For a beginner, though, Base R is a headache.
Take a look at this comparison. If you want to filter a dataset in Base R, you might write:df[df$age > 25 & !is.na(df$age), ]
It’s clunky. It’s easy to miss a comma. In a modern r tutorial in r, we use the pipe operator. It looks like this: |>. It basically means "and then."
So, the same command becomes:df |> filter(age > 25)
It reads like English. You take the data, and then you filter it. This makes your code readable to your future self when you open this project six months from now and have no idea what you were thinking.
Data Types: The Stuff That Breaks Your Code
You're going to get errors. Everyone does. Usually, it's because R thinks a number is a word.
- Numerics: Decimals like 10.5.
- Integers: Whole numbers, often denoted with an
L(like2L), though you rarely need to be that specific. - Characters: Text. Always in "quotes."
- Logicals: TRUE or FALSE. Note that R is case-sensitive.
Trueis nothing.TRUEis a logical value. - Factors: This is where R gets "statisticky." Factors are for categorical data—like "Small," "Medium," and "Large." They look like text, but they have an underlying integer structure.
If you try to add a character to a numeric, R will throw a fit. Use class(your_variable) to check what you’re dealing with. It’s the first thing you should do when an error message pops up.
Visualizing Success with ggplot2
People choose R for the graphics. Period.
The "gg" in ggplot2 stands for the Grammar of Graphics, a theory by Leland Wilkinson. The idea is that you build a plot in layers. You start with the data, then you define the "aesthetics" (what goes on the x-axis, what goes on the y-axis), and then you add a "geom" (a point, a line, a bar).
library(ggplot2)
ggplot(data = mpg, aes(x = displ, y = hwy)) +
geom_point(color = "blue") +
geom_smooth()
In those few lines, you’ve created a scatter plot with a trend line. It looks professional. It's publication-ready. That’s the power of R.
The Reality of Data Cleaning
Data is never clean. It’s a lie taught in textbooks.
Real data has typos. It has missing values (represented as NA in R). It has dates formatted in four different ways. This is where tidyr and stringr come in.
One common hurdle is "Long" vs. "Wide" data. Most people enter data in a "Wide" format because it's easy for humans to read. But R prefers "Long" data for analysis. The pivot_longer() function is your best friend here. It’s the "ctrl+alt+delete" of data reshaping.
📖 Related: Why Earth Is Still the Weirdest Thing in the Universe
Mistakes Everyone Makes (Including Experts)
Forget a comma? Code breaks.
Forget to close a parenthesis? Code breaks.
Forget that R is case-sensitive? Code breaks.
But the biggest mistake is not using the community. R has one of the most welcoming communities in tech. If you’re stuck, search for your problem on Stack Overflow or the RStudio Community forums. Chances are, someone else had that exact same error in 2014 and the solution is already there.
Also, look into R Markdown or Quarto. These tools let you combine your code, your charts, and your written explanation into a single document (like a PDF or an HTML page). It’s "reproducible research." If your data changes, you just click "Render," and the entire report updates itself. No more copy-pasting charts into Word.
Actionable Next Steps
To actually learn R, you have to stop reading and start typing.
- Install R and RStudio Desktop. It's free. It’s open source.
- Install the Tidyverse. Run
install.packages("tidyverse")in your console. - Use the built-in datasets. You don't need to find a CSV file yet. Type
data()to see a list of datasets already in R, likeirisormtcars. - Pick a small project. Don't try to solve world hunger. Try to visualize your own monthly spending or the scores of your favorite sports team.
- Master the Pipe. Get comfortable with
|>(or the older%>%). It’s the key to writing clean, logical code. - Read "R for Data Science" by Garrett Grolemund and Hadley Wickham. It is available for free online and is widely considered the "Bible" of modern R programming.
R isn't about being a "coder." It's about being an analyst who has better tools than a spreadsheet. Once you get past the initial learning curve, you'll find that tasks that used to take three hours in Excel now take three seconds in R. And that is a very good feeling.