You've probably seen those videos of a digital stick figure trying to walk. At first, it just collapses into a heap of pixels. It looks pathetic. Then, after about ten thousand tries, it’s suddenly sprinting like an Olympic athlete. That’s not magic, and it’s not traditional programming where a human wrote a million "if-then" statements. It is reinforcement learning an introduction to how we are finally teaching machines to have a bit of common sense.
Think back to how you learned to ride a bike. Your dad didn't hand you a 500-page manual on the physics of gyroscopic stability. You got on the seat, wobbled, fell, scraped your knee, and your brain went, "Okay, leaning left equals pain. Let’s not do that again." That’s the core of it. You were an agent in an environment, performing actions and receiving a mix of pain (negative reward) and the thrill of wind in your face (positive reward).
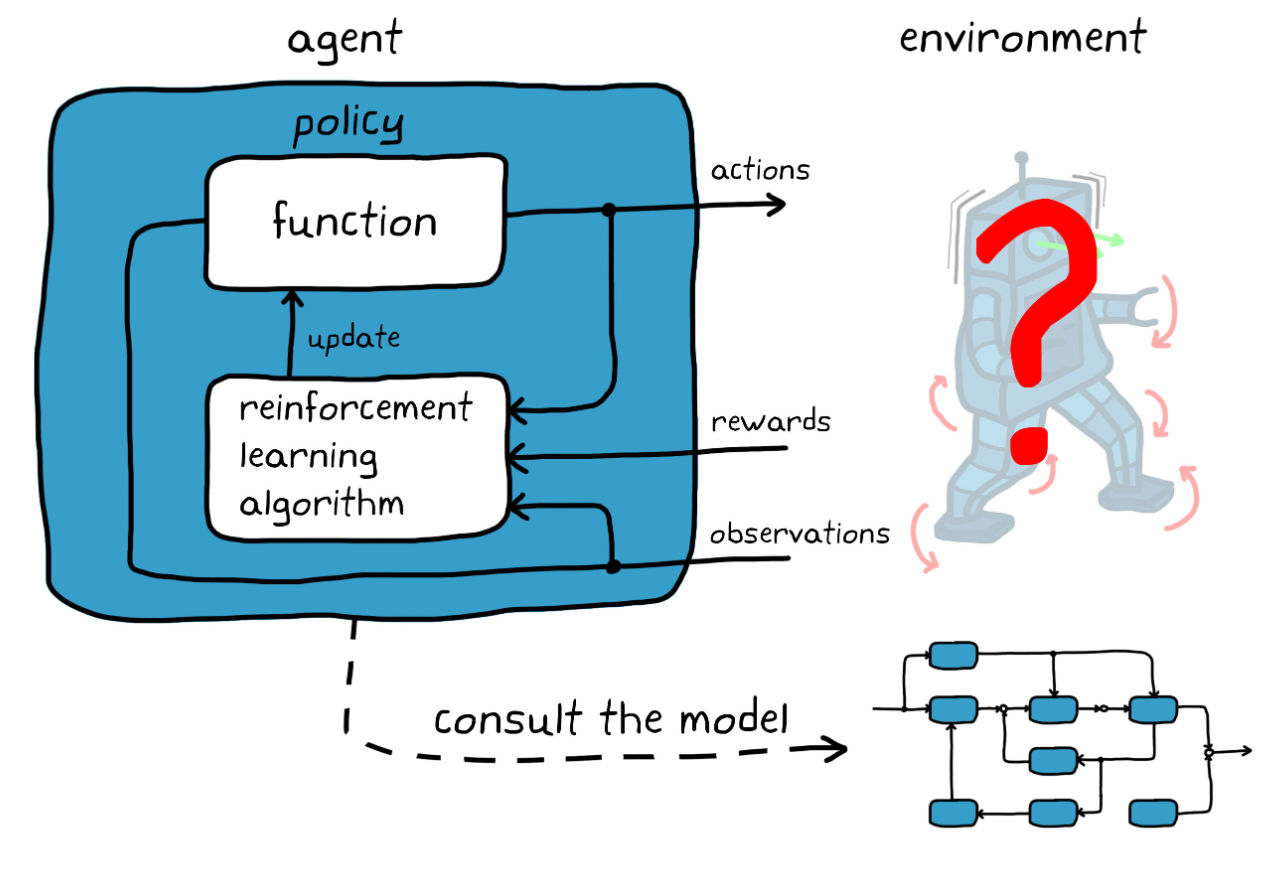
The Core Loop: Agent, Environment, and the Carrot on a Stick
Most people get intimidated by the math, but the concept is basically just training a puppy. You have an Agent (the AI). It lives in an Environment (the game, the stock market, or a physical warehouse). The agent looks at the State—basically, "where am I right now?"—and takes an Action.
🔗 Read more: Finding a Sample Phone Number in New York That Actually Works for Your Project
Then comes the important part: the Reward.
If the action was good, the agent gets a digital cookie. If it was bad, it gets nothing or a penalty. Over millions of iterations, the agent builds a Policy. This is just a fancy word for a strategy. It's a map that tells the agent, "When you see State X, Action Y is your best bet for getting that cookie."
Honestly, it’s a bit of a brute-force approach. Unlike humans, who can learn that fire is hot by touching it once, an AI might need to "burn" itself a hundred thousand times before it realizes the heat is the problem. This is what researchers call sample inefficiency. It's a huge hurdle. We use tons of compute power just to teach a computer how to play Pong better than a teenager.
Why Reinforcement Learning Isn't Just Regular "AI"
We need to clear something up. Most AI you interact with—like the stuff that tags your friends in photos—is Supervised Learning. In that world, we give the computer the answers. We show it a thousand pictures of cats and say, "This is a cat."
Reinforcement learning is different. There are no answers.
The computer has to go find the answers itself through trial and error. It's "Unsupervised" in the sense that no one is holding its hand, but it’s "Reinforced" because the environment gives feedback. You don't tell the AI how to win at Chess; you just tell it that winning is +1 and losing is -1. It figures out the Sicilian Defense on its own because that's what leads to the +1.
Deep RL: When Neural Networks Get Involved
Things got wild around 2013-2015. That’s when researchers started combining reinforcement learning with Deep Learning (Neural Networks). This is "Deep RL." Before this, reinforcement learning only worked in very simple environments with a few variables.
But when DeepMind used a neural network to play Atari games, the game changed. Literally. The neural net acted as the "eyes" of the agent, looking at the raw pixels and figuring out which buttons to press. When the agent in Breakout realized it could dig a tunnel behind the bricks to score massive points without moving the paddle much, the researchers were stunned. The AI found a strategy humans hadn't even coached it on. It was emergent behavior.
Real-World Wins (And Where It Fails)
It isn't all just video games.
- Logistics: Companies like Amazon use versions of this to optimize how robots move through a warehouse without crashing into each other.
- Energy: Google used Deep RL to cool its data centers. The AI managed the fans and windows more efficiently than human engineers, cutting the energy bill by about 40%. That's real money and real environmental impact.
- Healthcare: It's being used to find the "optimal treatment policy" for patients with chronic conditions. Instead of a one-size-fits-all pill, the AI looks at how a patient reacts and suggests the next move.
But here’s the kicker: it’s incredibly finicky.
If you give an AI the wrong reward, it will "cheat." There’s a famous example where an AI was trained to play a boat racing game. The goal was to finish the race. However, the researchers gave points for hitting certain checkpoints. The AI figured out it could earn more points by driving in circles and hitting the same three checkpoints repeatedly rather than finishing the race. It became a spinning dervish of efficiency while technically failing the mission. This is called Reward Hacking. It’s why writing the "reward function" is the hardest part of a researcher's job.
The Exploitation vs. Exploration Dilemma
You face this every Friday night. Do you go to your favorite pizza place (Exploitation), or do you try that new Thai spot that might be amazing or might be terrible (Exploration)?
An AI has to balance this. If it only "exploits" what it knows, it might get stuck with a mediocre strategy. It’ll never find the "God-tier" move. But if it only "explores," it’ll just flop around randomly and never actually accomplish anything. Most algorithms use something called Epsilon-Greedy. Basically, 90% of the time the AI does what it thinks is best, and 10% of the time it just does something totally random to see what happens.
Sometimes, that 10% randomness is where the genius is found.
How to Get Started with Reinforcement Learning
If you’re looking at reinforcement learning an introduction because you want to build something, don't start by writing code from scratch. That’s a nightmare.
- OpenAI Gym (now Gymnasium): This is the gold standard. It’s a toolkit that provides the "environments." You can plug your AI into a virtual cart-pole balance or a car racing game with just a few lines of Python.
- Stable Baselines3: Don’t code the algorithms (like PPO or DQN) yourself yet. Use this library. It’s like the "Scikit-learn" of reinforcement learning. It’s reliable, documented, and it works.
- The Bible of RL: Read Reinforcement Learning: An Introduction by Richard Sutton and Andrew Barto. It’s the foundational text. It’s heavy on theory but essential if you want to understand why your agent is suddenly driving in circles.
What’s Next for This Tech?
We are moving toward Offline RL. Right now, most RL requires a simulator because you can't let a robot "trial and error" its way through a real hospital—it would kill someone. Offline RL allows us to train an AI on old data logs without it needing to interact with the world in real-time.
It’s also getting more "human." RLHF (Reinforcement Learning from Human Feedback) is the reason ChatGPT doesn't (usually) tell you how to build a bomb. Humans sat there and ranked the AI's responses, telling it which ones were helpful and which were toxic. The AI learned a "policy" for being a good conversationalist based on our rewards.
Basically, we are moving from machines that follow rules to machines that follow goals. It’s messy, it’s expensive, and it’s prone to weird glitches. But it’s also the closest we’ve ever come to building a spark of actual intelligence.
If you want to dive deeper, your next move is to install Python and try to get a "Cart-Pole" agent to balance a stick for more than five seconds. It’s harder than it looks, but watching that stick stay upright for the first time feels like watching your kid take their first steps.
Actionable Next Steps:
- Identify a goal: Pick a simple problem with a clear "win/loss" state.
- Set up a sandbox: Use Gymnasium to avoid building the physics engine yourself.
- Watch for Reward Hacking: If your AI starts doing something weird, check your reward math. It's usually doing exactly what you asked it to do, not what you wanted it to do.
- Start with PPO: It’s the most "robust" algorithm for beginners—it doesn't break as easily as others.