The AI world moves fast, but the jump to Wan2.2 felt like someone swapped a bicycle for a jet engine overnight. If you've been messing around with Stable Diffusion or Flux, you've probably heard the buzz. Alibaba's Tongyi Wanxiang team basically dropped a bomb on the open-source community by releasing a model that actually understands cinematic lighting better than some film school grads.
But here is the thing. Most people are trying to use the Wan2.2 text to image workflow like it's just another version of SDXL. It isn't. Honestly, if you treat it that way, you’re going to get weird, blurry messes or results that look like they were pulled from a 2022 fever dream.
Why Wan2.2 Isn't Just "Another Model"
Basically, Wan2.2 is a video model first. That sounds counterintuitive when you just want a still image, right? But because it’s built on a Mixture-of-Experts (MoE) architecture—specifically designed to handle complex temporal motion—it has a deep, "world-model" understanding of physics and light. When you "freeze" it to generate a single frame, you get an image with a level of realism and structural integrity that's hard to find elsewhere.
The architecture uses a high-noise expert and a low-noise expert. Think of it like a master painter and a detail-obsessed restorer working on the same canvas. The high-noise expert sets the stage—the composition, the big shapes, the "vibe." Then, the low-noise expert steps in to handle the fine textures, the skin pores, and how light bounces off a rainy sidewalk.
If you don't manage the handoff between these two experts in your workflow, the image falls apart.
The Local Hardware Reality Check
Let's talk about VRAM because that's where the dreams usually die.
If you’re running an RTX 4090, you're golden. You can run the 14B model without breaking a sweat. But what if you’re on a laptop with 8GB or an older 3060? You've got options, but you need to be smart. The Wan2.2 text to image workflow can be heavy.
- The 14B MoE Model: This is the flagship. It needs about 20GB of VRAM in its raw state.
- The 5B Dense Model: This is the "people's model." It runs on 8GB of VRAM and is surprisingly fast. Honestly, for most text-to-image tasks, the 5B is more than enough.
- Quantization (GGUF): If you're struggling, look for GGUF versions. They compress the model so it fits into smaller cards. You might lose 2-5% in quality, but it's better than getting an "Out of Memory" error every five minutes.
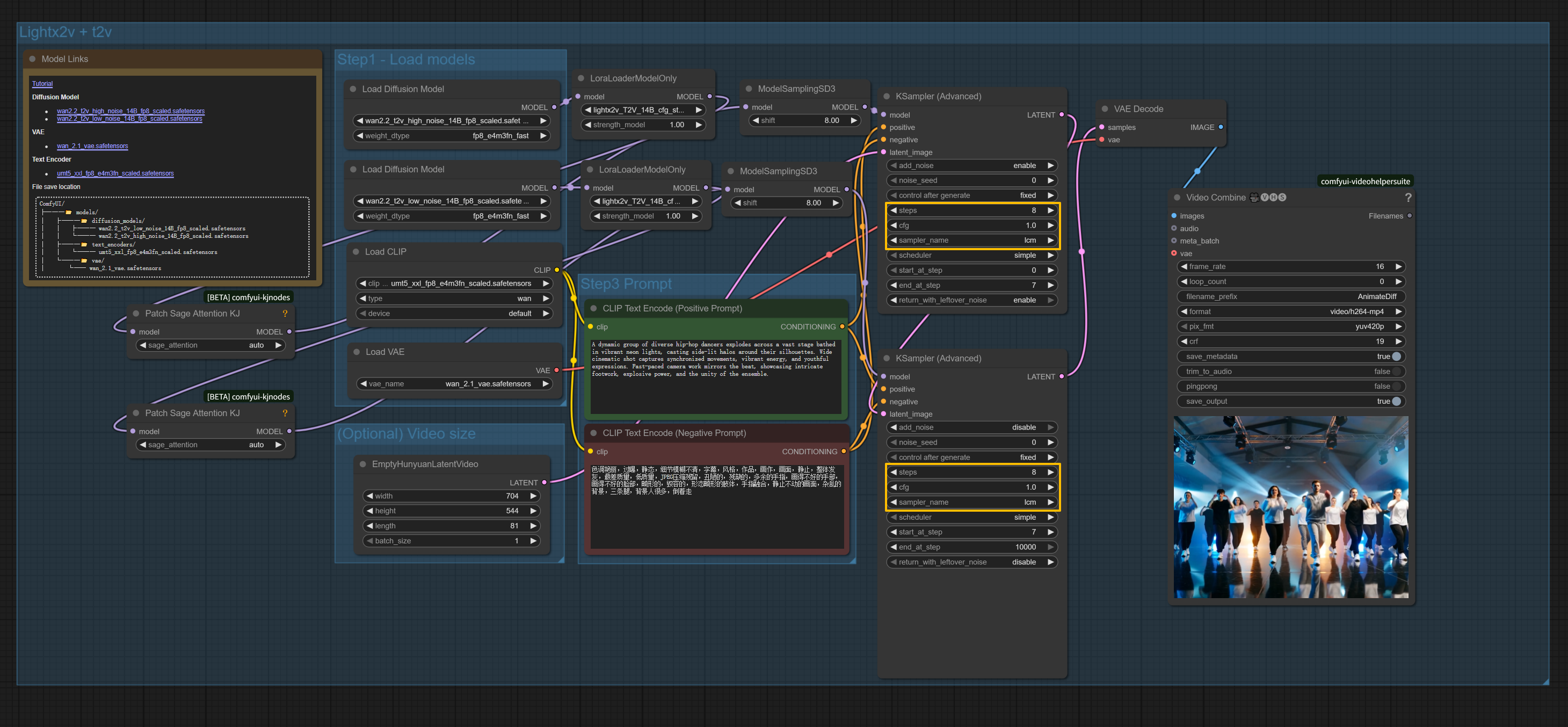
Setting Up the Perfect ComfyUI Workflow
Most of the pros are using ComfyUI for this. It’s nodal, it’s messy, and it’s powerful. To get a high-quality static image, you basically set the frame count to 1. This "tricks" the video model into focusing all its latent energy on a single, high-fidelity frame.
The Handoff (The Switch Step)
This is the most critical part of the Wan2.2 text to image workflow. Since we have two experts, you have to decide when the high-noise expert stops and the low-noise one starts.
Typically, you’ll run about 20 to 30 steps total. A common mistake is switching too late. If you stay in the high-noise expert for 25 out of 30 steps, your image will be grainy and lack detail. If you switch too early, the composition might be "mushy." A sweet spot is usually around step 8 or 10. This gives the "architect" enough time to build the house before the "decorator" comes in to do the trim.
🔗 Read more: Why Everyone Is Starting to Talk to AI Characters (and What’s Actually Happening)
Prompting Like a Cinematographer
Forget the "masterpiece, 8k, highly detailed" tag soup. Wan2.2 was trained on a massive dataset (+65.6% more images than version 2.1) with very specific aesthetic labels. It understands "rim lighting," "depth of field," and "anamorphic lens flare."
Instead of saying "a woman in a forest," try "low-angle tracking shot of a woman walking through a misty pine forest, soft morning light filtering through needles, cinematic color grading, 35mm film grain." The model actually knows what those words mean. It's refreshing.
Common Pitfalls and How to Dodge Them
One thing people notice is that Wan2.2 can sometimes feel "flatter" than Flux or Stable Diffusion if you don't push the CFG. However, Wan2.2 is very sensitive to CFG values.
🔗 Read more: Is the Tidal Free 3 Month Trial Still Real? What You Need to Know Before Signing Up
If you go too high (above 6 or 7), you’ll get that "deep-fried" AI look where the colors are way too saturated. Stay between 2.0 and 4.5 for the most realistic results. Also, keep an eye on the "Model Shift" settings in ComfyUI. Setting the shift values to 1.0 in the ModelSampling nodes helps the model maintain scene complexity without getting overwhelmed by noise.
What's Next for Your Workflow?
Once you've mastered the static image, the real power of Wan2.2 is its ability to animate that exact same scene. Since the Wan2.2 text to image workflow uses the same base architecture as the image-to-video (I2V) path, you can generate a perfect still and then use it as a "starting frame" to create a 5-second cinematic clip.
Don't just stop at the default settings. Experiment with different schedulers. While "Euler" is the old reliable, many creators are finding that "res_multistep" or "sgm_uniform" produces much cleaner textures in the low-noise phase. It’s all about trial and error.
Actionable Next Steps:
- Update ComfyUI: Use the Manager to make sure you're on the latest version; native support for Wan2.2 was added recently and it’s much more stable now.
- Download the 5B FP8 Model: If you have less than 12GB of VRAM, don't even bother with the 14B initially. Start with the 5B to get a feel for the prompting.
- Use a "One-Frame" Workflow: Look for JSON templates specifically labeled for Wan2.2 Text-to-Image. These usually have the "EmptyHunyuanLatentVideo" node pre-configured for a single frame.
- Practice Cinematic Prompting: Stop using generic descriptors and start using film terminology. The results will shock you.