You're sitting in a stats class, or maybe you're staring at a massive dataset at work, and someone mentions the "bell curve." It sounds simple enough. But then, they hand you this terrifying grid of decimals. The z normal distribution table. Honestly, it looks like something out of a 1950s cryptography manual.
It’s easy to think this is a relic. We have Python. We have R. We have calculators that can do the heavy lifting in milliseconds. Yet, if you don't understand how to read that grid, you're basically flying a plane without knowing how the altimeter works. You might stay in the air, but you won't know why.
📖 Related: How to View Public IG Story Posts Without Leaving a Digital Footprint
What are we actually looking at?
At its core, the z normal distribution table is a map of probability. Think of it as a way to standardize the chaos of the world.
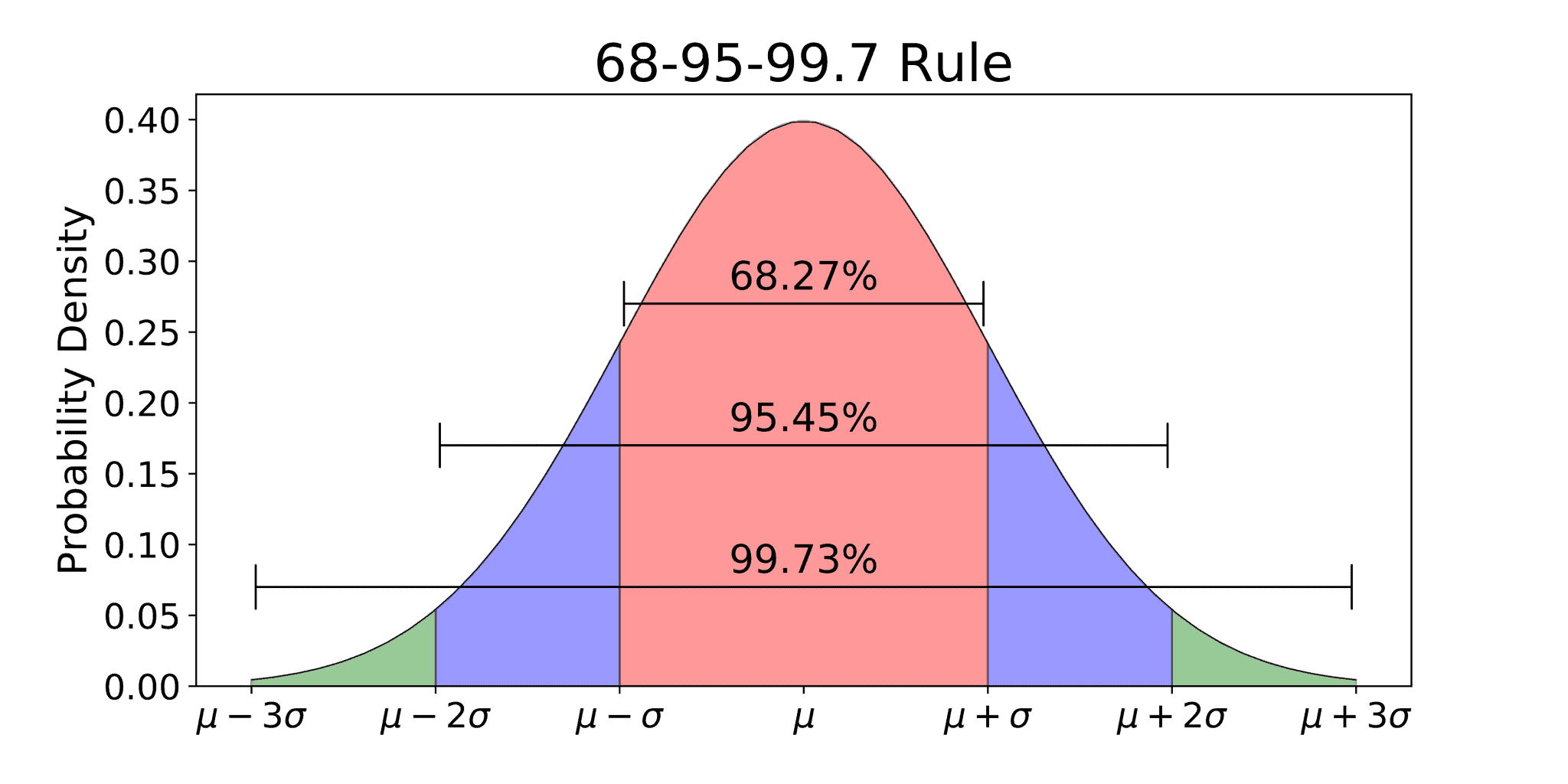
Nature loves the normal distribution. Heights of adult men, the weight of apples in an orchard, even the errors made by a precision laser—they all tend to cluster around an average. This is the Gaussian distribution, named after Carl Friedrich Gauss. He was a genius, but even he knew that raw data is messy.
To make sense of it, we use the Z-score formula:
$$z = \frac{x - \mu}{\sigma}$$
Here, $x$ is your data point, $\mu$ is the mean, and $\sigma$ is the standard deviation. This little bit of math strips away the units. It doesn't matter if you're measuring centimeters, volts, or dollars. Once you have a Z-score, you're just looking at how many standard deviations you are away from the center.
The table then tells you the "area under the curve." That area? It’s the probability. If your Z-score is 0, you're right in the middle. The table will tell you 0.5000, meaning 50% of the data falls below you.
✨ Don't miss: Co-intelligence: Living and Working with AI and Why We’re All Doing It Wrong
The quirk of the "Standard" table
Here is where it gets weird. Not all tables are created equal.
Some tables are "cumulative from the left." They start at the far left tail and tell you everything up to your Z-score. Others are "center-out," starting from zero and moving right. If you grab the wrong one during an exam or a high-stakes project, your results will be catastrophically wrong. Always check the little shaded diagram at the top of your table. It’s the legend for your map.
I remember a colleague who was analyzing manufacturing defects. He kept getting p-values that made no sense. He was using a "tail-end" table but treating it like a cumulative one. He thought 2% of the parts were failing when, in reality, it was nearly 48%. Details matter.
Why not just use a computer?
You should. Use Excel's =NORM.S.DIST() or Python's scipy.stats. But the z normal distribution table teaches you the "geometry" of data.
When you look at the table, you notice the numbers don't grow linearly. The difference between a Z-score of 0.1 and 0.2 is huge compared to the difference between 3.8 and 3.9. This is because the bell curve thins out. The "tails" contain very little probability. This is why "Six Sigma" in business is such a big deal. It’s aiming for a Z-score of 6, where the probability of an error is so infinitesimally small it’s practically zero.
Real world: The 1970 Blue Ribbon Sports Example
Let's look at a real-world scenario, albeit simplified for clarity. Imagine you’re running a small shoe company (like the early days of Nike, then Blue Ribbon Sports). You know the average foot size for your target demographic is 10 inches with a standard deviation of 0.5 inches.
You want to know what percentage of men will need a shoe larger than 11 inches.
First, calculate the Z-score. 11 minus 10 is 1. Divide that by the standard deviation of 0.5. Your Z-score is 2.0.
Now, go to your z normal distribution table. Look for 2.0 in the left column and .00 in the top row. You’ll find the value 0.9772. This means 97.72% of men have feet smaller than 11 inches. To find those with larger feet, you subtract from 1. Only about 2.28% of your customers need that size.
🔗 Read more: Black Hat vs Red Hat: Why The Security World Is Actually Terrified of Both
If you over-produce that size, you lose money. If you under-produce, you lose customers. That’s the power of the table. It turns "I think" into "I know."
Common traps and misconceptions
People often think a negative Z-score is "bad." It's not. It just means you're below the average. If you're measuring blood pressure or golf scores, a negative Z-score is usually great news.
Another mistake? Assuming everything is normally distributed. It isn't. Wealth is not normal; it follows a power law. Stock market returns are "fat-tailed," meaning extreme events happen way more often than a z normal distribution table would predict. This is what Nassim Taleb talks about in The Black Swan. If you use a Z-table to predict a market crash, you might end up broke because the table assumes the "tails" are thinner than they actually are in finance.
Reading the table like a pro
The table is usually laid out with the first decimal of the Z-score on the Y-axis and the second decimal on the X-axis.
Suppose you have a Z-score of 1.96.
- Trace down the left side to 1.9.
- Slide your finger to the right until you hit the column for 0.06.
- The intersection is 0.9750.
This specific number, 1.96, is the "magic number" in statistics. It leaves exactly 2.5% in the upper tail. If you're doing a two-tailed test, it accounts for the 5% "alpha" or error rate that scientists use to claim something is "statistically significant."
Putting this to use today
Stop looking at the table as a homework assignment. Use it as a filter.
Next time you see a headline saying "Average IQ has dropped by 3 points," don't panic. Look at the standard deviation (usually 15). Calculate the Z-score. You'll likely see that a 3-point shift is a tiny movement on the z normal distribution table. It’s noise, not a signal.
Actionable Next Steps
- Download a PDF: Keep a standard cumulative "left-to-right" Z-table on your desktop. It's faster than googling it every time.
- Practice the "Inverse": Try to find a probability first (like 0.95) and work backward to find the Z-score (1.645). This is how you set confidence intervals.
- Verify your Tools: If you use Excel, run a test. Type
=NORM.S.DIST(1.96, TRUE)and see if it matches your table. If it doesn't, you're likely using a different type of table (like a "mean-to-Z" table). - Check for Normality: Before you ever touch a Z-table in a real project, run a Shapiro-Wilk test or look at a Q-Q plot. If your data isn't a bell curve, the Z-table will lie to you.
Understanding the z normal distribution table isn't about memorizing decimals. It’s about recognizing the underlying rhythm of the world. It’s about knowing where the crowd is and, more importantly, how far away the outliers are standing. It’s old school, sure. But so is the wheel, and we still use that every day.